浏览器
浏览器的组成
- 渲染引擎(即内核)
用来解析 HTML 和 CSS 这是浏览器兼容性问题出现的根本原因 常见浏览器的内核
| 浏览器 | 内核 |
|---|---|
| chrome | Blink |
| 欧鹏 | Blink |
| 360 安全浏览器 | Blink |
| 360 极速浏览器 | Blink |
| Safari | Webkit |
| Firefox 火狐 | Gecko |
| IE | Trident |
- js 引擎
用来解析网页中的 js 代码,处理后再运行
| 浏览器 | JS 引擎 |
|---|---|
| chrome / 欧鹏 | V8 |
| Safari | Nitro |
| Firefox 火狐 | SpiderMonkey(1.0-3.0)/ TraceMonkey(3.5-3.6)/ JaegerMonkey(4.0-) |
| Opera | Linear A(4.0-6.1)/ Linear B(7.0-9.2)/ Futhark(9.5-10.2)/ Carakan(10.5-) |
| IE | Trident |
浏览器的多进程架构
进程和线程
进程是一个程序的运行实例。当我们启动一个程序,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程 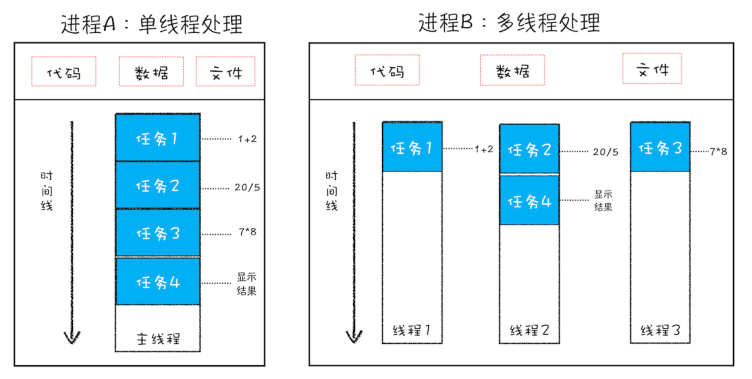 线程依附于进程,由进程来启动和管理。 线程与进程之间的关系有以下特点
线程依附于进程,由进程来启动和管理。 线程与进程之间的关系有以下特点
- 进程中任一线程执行出错,都会导致整个进程的崩溃,如果程序只有一个进程,那么很容易崩溃掉
- 线程之间可以共享进程中的数据,都能进行读写操作
- 一个进程关闭,操作系统会回收进程所占用的内存,即使某线程存在内存泄漏问题,内存也能被正确回收
- 进程之间的内容相互严格隔离。如果需要通信,需要进程间通信(IPC)的机制 《进程间的通信方式》
单进程浏览器
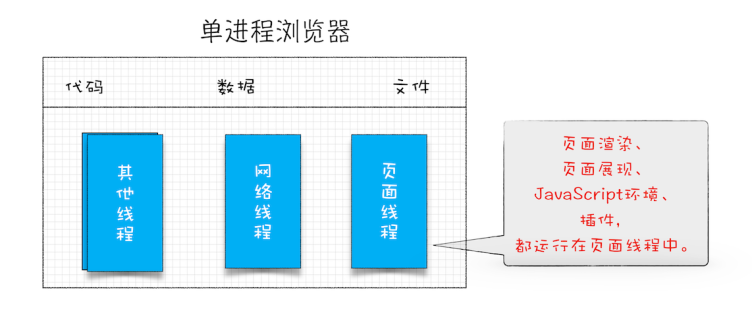
存在的问题
- 不稳定。早期浏览器依赖各种插件实现 web 游戏、web 视频,但是插件容易出问题,任意一个线程挂掉都会导致整个浏览器的崩溃
- 不流畅。一个线程需要处理多个模块,比如页面线程需要同时处理页面渲染、页面展现等等,但是同一时刻只有一个模块能执行,造成长时间的等待、卡顿。同时,对于复杂的页面,如果页面内存泄漏,会存在内存不能完全回收的情况,因此导致使用时间越长,内存占用越高,浏览器越慢
- 不安全。恶意插件、恶意脚本
进程结束时,内存总会被正确回收。 但线程结束时,可能存在内存泄漏的情况,所以在单进程的浏览器,打开和关闭的页面更多,浏览器就可能变得越来越卡顿。
多进程浏览器
以 Chrome 举例
早期多进程浏览器
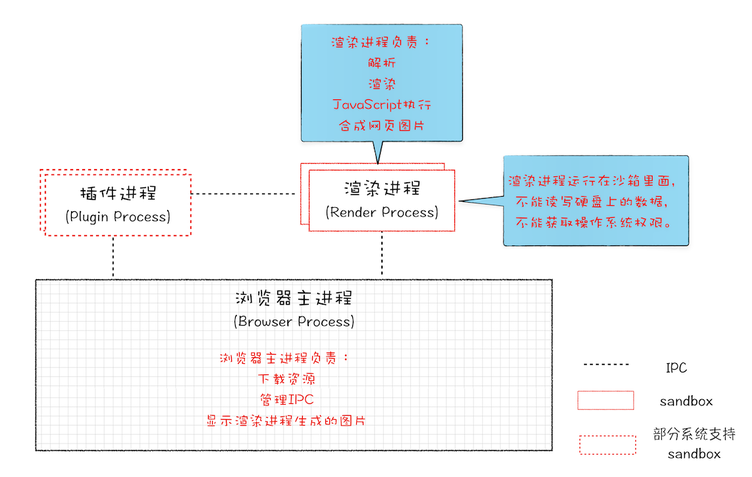
- 解决不稳定问题。进程相互隔离,一个页面或者插件崩溃,不影响浏览器和其他进程
- 解决不流畅问题。不同站点的页面有自己的渲染进程,所以即便存在比如 js 阻塞渲染进程的情况,也只会影响当前页面
- 解决不安全问题。使用安全沙箱,Chrome 把插件和渲染进程锁在沙箱里面,沙箱里的程序无法访问硬盘和敏感位置。
当前多进程浏览器
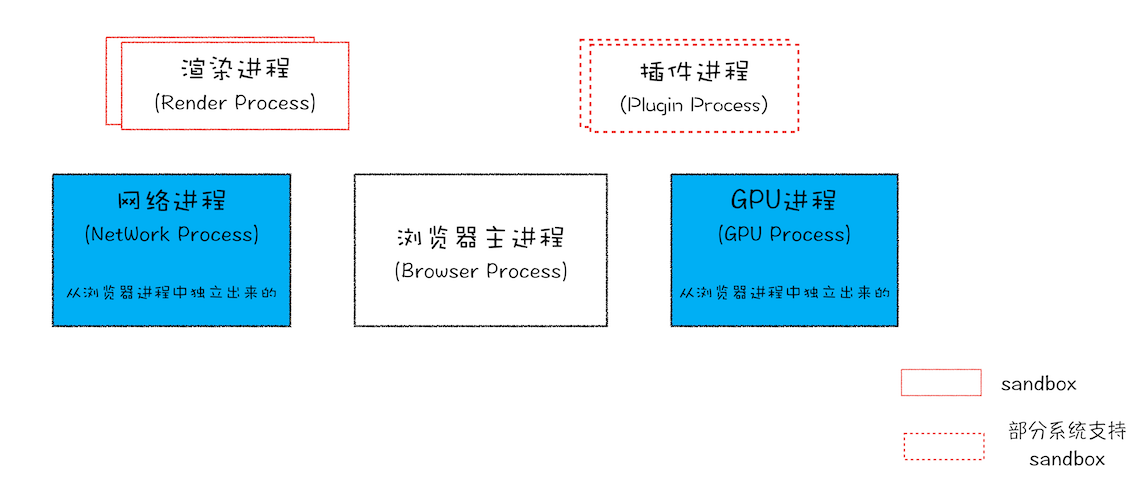
- 浏览器进程。界面显示、用户交互、子进程管理、存储
- 渲染进程。解析、渲染、执行 js,排版引擎 Blink 和 js 引擎 V8 都是运行在该进程中。渲染进程都运行在安全沙箱
- GPU 进程。GPU 最初是为了实现 3d css,但是后来网页和 Chrome 的 UI 界面都采用 GPU 绘制,GPU 成为普遍需求后,Chrome 的多进程架构引入了 GPU 进程。
- 网络进程。网络资源加载,独立了出来
- 插件进程。运行插件
存在问题:
- 更高资源占用。每个进程都包含公共基础结构的副本如 js 运行环境
- 更复杂的体系架构。浏览器模块间耦合性高、拓展性差
未来面向服务的架构
“面向服务的架构”(Services Oriented Architecture,简称 SOA) 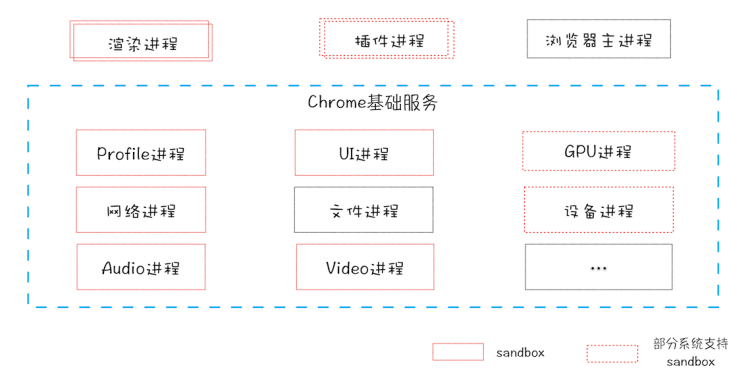 原来的各种模块重构成独立的服务,每个服务都可以在独立的进程中运行 最终把 UI、数据库、文件、设备、网络等模块重构为基础服务 Chrome 还能根据设备性能调整架构,在性能较差的设备上将服务整合到一个进程中。
原来的各种模块重构成独立的服务,每个服务都可以在独立的进程中运行 最终把 UI、数据库、文件、设备、网络等模块重构为基础服务 Chrome 还能根据设备性能调整架构,在性能较差的设备上将服务整合到一个进程中。 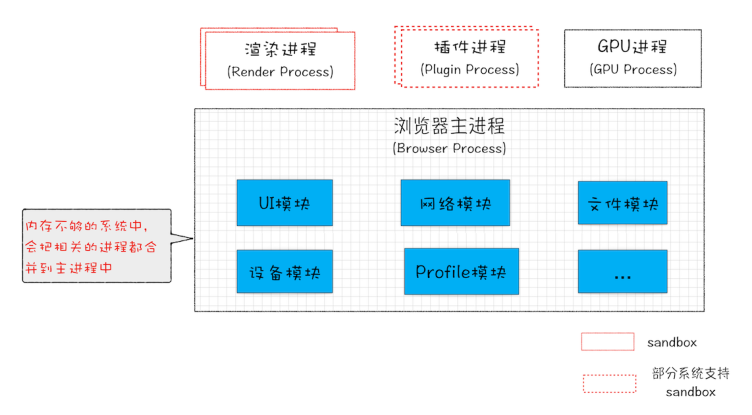
浏览器是怎么工作的
从一个 URL 到网页
- 浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面;
- 把请求回来的 HTML 代码经过解析,构建成 DOM 树;
- 计算 DOM 树上的 CSS 属性,构建 CSS 树;
- 根据 CSS 属性对元素逐个进行渲染,得到内存中的位图;一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度;
- 合成之后,再绘制到界面上。
用户输入
在地址栏中输入一个查询关键字,地址栏会判断关键字是搜索内容还是请求的 URL
- 搜索内容:使用搜索引擎合成新的带搜索关键字的 URL
- URL:加上协议,合成完整的 URL
输入完,按下回车后,跳转页面前,还有一次 beforeunload 事件的机会,可以用于数据清理,或者询问用户是否确认离开或者提交表单
URL 请求
浏览器通过进程间通信把 URL 发送给网络进程 首先,网络进程会先查找本地缓存是否缓存了该资源,有就直接返回该资源给浏览器,没有就进入网络请求流程。 请求前先进行 DNS 解析,以获取请求域名的服务器 IP 地址,如果请求协议是 HTTPS,那么还需要建立 TLS 连接
DNS 解析
在浏览器输入网址,其实就是像服务器请求我们想要的页面内容
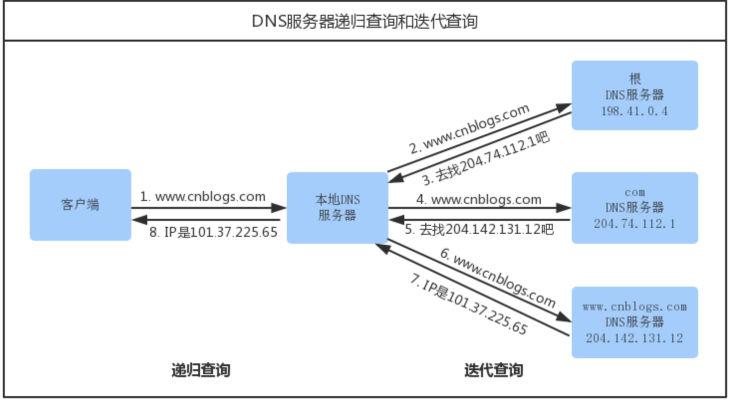
客户端收到输入的域名地址后,会先去找本地的 hosts 文件,检查是否有对应的域名 如果有就去向其 IP 地址发送请求,没有就去找 DNS 服务器,通过递归查询本地服务器和迭代查询 DNS 服务器获取到 IP 地址的响应报文 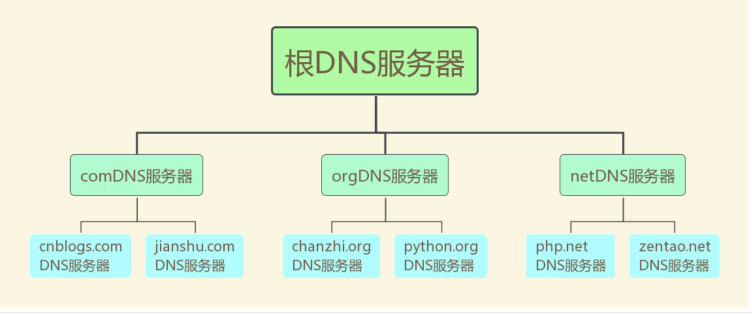
TCP 连接
拿到 IP 后,下一步要通过三次握手链接到服务器, 要进行 TCP 连接,连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的 Cookie 等数据附加到请求头中,然后向服务器发送构建的请求信息。 请求连接(SYN 数据包) 服务器 客户端 确认信息(SYNJACK 数据包) 握手结束(ACK 数据包) 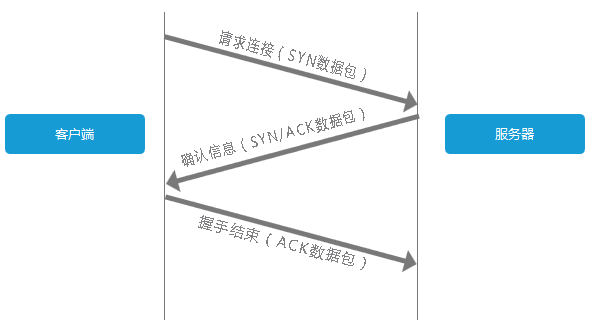
HTTP 请求
HTTP 是纯粹的文本协议,基于 TCP 协议,是传输文本格式的一个应用层协议。 使用 telnet 发送 HTTP 请求
telnet time.geekbang.org 80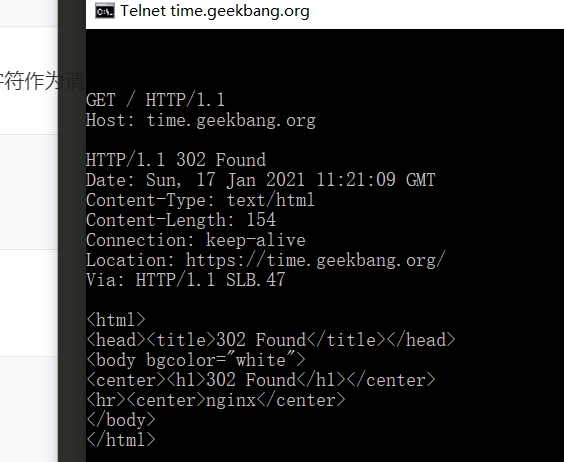 请求部分第一行称作 request line,包括请求的方法、路径、协议、协议版本, 响应部分第一行称作 response line,包括协议、版本、状态码、状态文本, 随后的由一个空行(两个换行符)分割的两部分,是请求/响应头和请求/响应体
请求部分第一行称作 request line,包括请求的方法、路径、协议、协议版本, 响应部分第一行称作 response line,包括协议、版本、状态码、状态文本, 随后的由一个空行(两个换行符)分割的两部分,是请求/响应头和请求/响应体 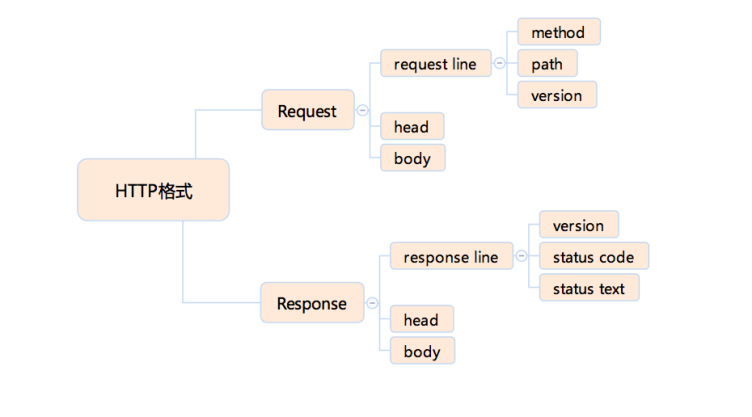
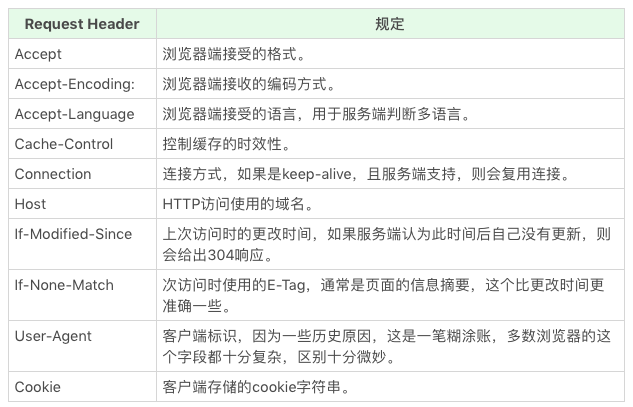
HTTP 头
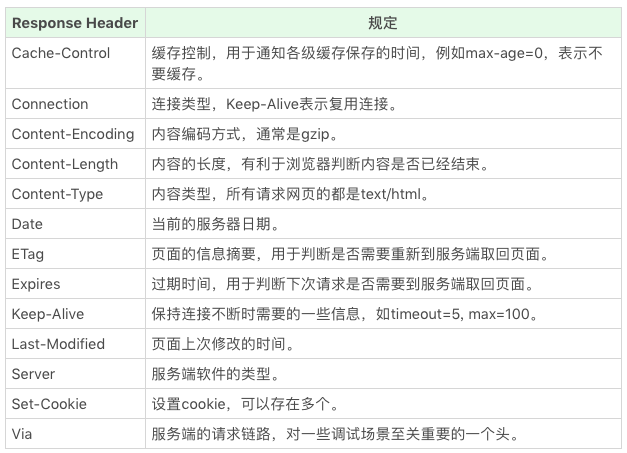
HTTP 体
常见的 body 格式:
- application/json
- application/x-www-form-urlencoded
- multipart/form-data
- text/xml
这是一种媒体类型标准(MIME),表示文档、文件、字节流的性质和格式 结构是 type/subtype,type 表示可以被分为多个子类的独立类别,subtype 表示细分的类型
浏览器通常使用 MIME 类型(而不是文件扩展名)来确定如何处理 URL,因此 Web 服务器在响应头中添加正确的 MIME 类型非常重要。如果配置不正确,浏览器可能会曲解文件内容,网站将无法正常工作,并且下载的文件也会被错误处理。
HTTPS
作用:
- 确定请求的目标服务端身份
- 保证传输的数据不被网络中间节点窃听或者篡改
HTTPS 首先与服务端简历一条加密通道 TLS,TLS 基于 TCP
HTTP2
是 HTTP1.1 的升级版本
- 支持服务端推送。服务端推送能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存当中,这可以避免客户端请求顺序带来的并行度不高,从而导致的性能问题。
- 支持 TCP 连接复用,则使用同一个 TCP 连接来传输多个 HTTP 请求,避免了 TCP 连接建立时的三次握手开销,和初建 TCP 连接时传输窗口小的问题。
服务器处理请求
服务器端收到请求后由 web 服务器处理请求, 如 apache、ngnix 等,解析用户请求后知道了需要调度哪些资源文件 再通过这些资源文件处理用户请求和参数,最后将结果通过 web 服务器返回给浏览器 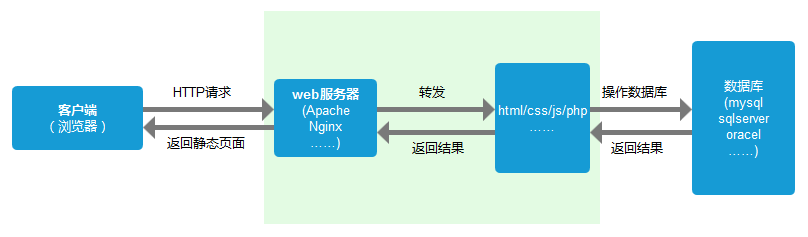 响应也是报文,响应结果中会有一个 HTTP 状态码,代表对应的错误的信息。如 200 代表请求成功且处理完毕 假如返回 301 或者 302,说明服务器需要浏览器重定向到其他 URL,这时网络进程会从响应头的 Location 字段读取重定向地址,然后再发起新的请求 跳转之后,浏览器会根据 HTTP 请求头中的 Content-Type 的值来决定显示响应体的内容 这时,如果设置错了 mime 类型,浏览器可能会曲解内容
响应也是报文,响应结果中会有一个 HTTP 状态码,代表对应的错误的信息。如 200 代表请求成功且处理完毕 假如返回 301 或者 302,说明服务器需要浏览器重定向到其他 URL,这时网络进程会从响应头的 Location 字段读取重定向地址,然后再发起新的请求 跳转之后,浏览器会根据 HTTP 请求头中的 Content-Type 的值来决定显示响应体的内容 这时,如果设置错了 mime 类型,浏览器可能会曲解内容
关闭 TCP 链接
当双方没有请求或响应传递时,任意一方都可以发起关闭请求,需要 4 次挥手 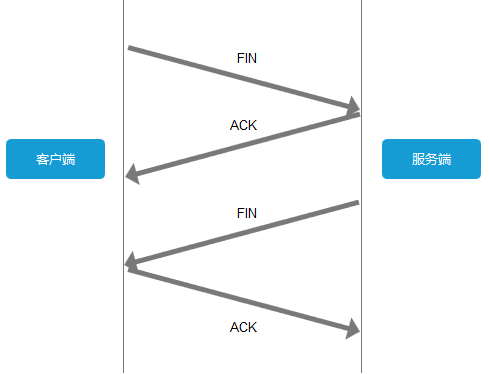 至此,资源获取完毕,开始渲染啦
至此,资源获取完毕,开始渲染啦
渲染主线程
渲染进程准备阶段
Chrome 为每个页面分配一个渲染进程,但如果是 根域名(xxx.com)和协议 相同的同一站点,新页面会复用父页面的渲染进程,官方称这种策略为 process-per-site-instance 比如
URL 初探 此时还不能进入文档解析状态,数据还在网络进程中
提交文档阶段
- 浏览器进程接收到网络进程的响应数据,向渲染进程发起“提交文档“的消息
- 渲染进程与网络进程建立传输数据的管道
- 数据传输完成,渲染进程返回“确认提交”信息给浏览器进程
- 浏览器进程收到“确认提交”消息,更新浏览器洁面状态,包括安全状态、地址栏 URL、前进后退的历史状态,然后更新 web 页面,此时进入渲染阶段
因此我们输入一个地址并回车后,页面并没有马上消息,要等一会儿才更新页面
解析 HTML
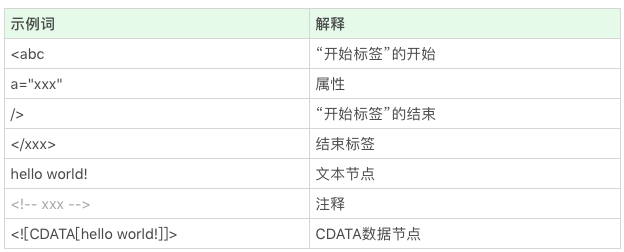
词法分析
<p class="a">text text text</p>以上 HTML 片段会被拆分成词(token)
<p“标签”的开始;class=“a”属性;>“标签”的结束;- text text text 文本;
</p>标签结束。
 把字符流解析成词的最常见方案是使用 状态机
把字符流解析成词的最常见方案是使用 状态机
状态机
初始状态,区分“<”“非<” 出现“<”可以认为进入一个标签状态,“非<”可以认为进入一个文本节点 进入标签状态还需要区分:
| 下一个字符 | 分析 |
|---|---|
| ! | 注释节点或者 CDATA 节点 |
| / | 结束标签 |
| 字母 | 开始标签 |
构建 DOM 树
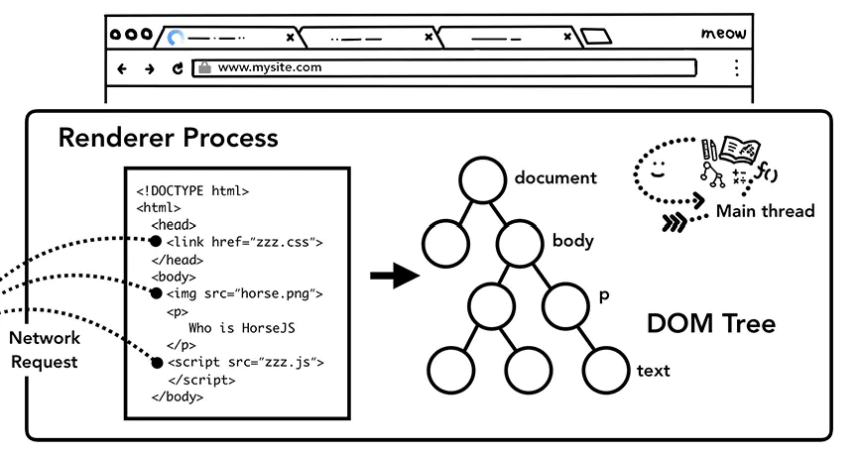 用 js 模拟 HTML 的语法分析器
用 js 模拟 HTML 的语法分析器
/*receiveInput负责接收词法部分产生的词
接收的同时,构建DOM树,栈顶就是最后的根节点
dom树的产出就是这个stack的第一项*/
function HTMLSyntaticalParser() {
let stack = [new HTMLDocument()];
this.receiveInput = function (token) {
/*
1. 栈顶元素就是当前节点;
2. 遇到属性,就添加到当前节点;
3. 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点;
4. 遇到注释节点,作为当前节点的子节点;
5. 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点;
6. 遇到 tag end 就出栈一个节点(还可以检查是否匹配)。
*/
};
this.getOutput = function () {
return stack[0];
};
}可通过在浏览器控制台输入“document”后回车查看 dom 树结构
解析 CSS
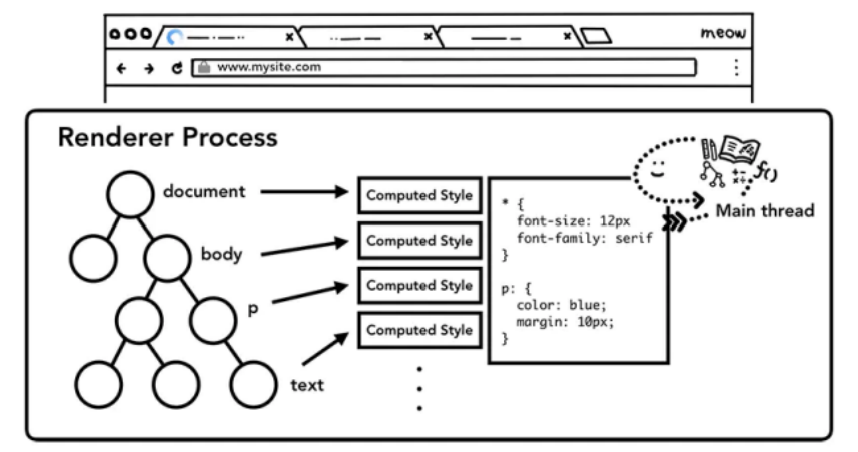 CSS 规则不是 DOM 结构建好了以后才添加样式的,而是依次拿到上一步构造好的元素,去检查匹配哪些规则再根据规则优先级进行覆盖和调整。不存在父选择器,选择器的出现顺序必定跟构建 DOM 树的顺序一致。
CSS 规则不是 DOM 结构建好了以后才添加样式的,而是依次拿到上一步构造好的元素,去检查匹配哪些规则再根据规则优先级进行覆盖和调整。不存在父选择器,选择器的出现顺序必定跟构建 DOM 树的顺序一致。
- 空格: 后代,选中它的子节点和所有子节点的后代节点。
: 子代,选中它的子节点。
- +:直接后继选择器,选中它的下一个相邻节点。
- ~:后继,选中它之后所有的相邻节点。
- ||:列,选中表格中的一列。
规则匹配的时候,也是要根据节点信息处理
可通过在浏览器控制台输入 document.styleSheets 查看 css 代码生成的结构
css 在被处理成 styleSheets 后,还要进行标准化,处理一些不被浏览器渲染引擎理解的属性值,例如: 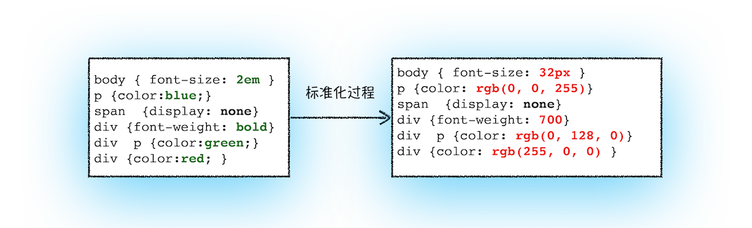
布局
有了 DOM 树和样式,还不足以显示页面,还需要给可见元素计算几何位置
创建布局树 LayoutTree
构建一棵只包含可见元素的布局树。
布局计算
计算布局树节点的坐标位置,重新写回布局树中。浏览器的基本布局方案是正常流排版,在此基础上支持绝对定位元素和浮动元素
正常流布局:顺次排布、折行,支持元素和文字的混排
绝对定位元素:把自身抽离正常流,依靠 top、left 等确定位置,不参加布局计算,不影响其他元素
浮动元素:使自身处于正常流的左或者右的边界,占据一块空间
除此之外,还有 flex、grid 等布局方式
分层
针对复杂的 3d 变换、页面滚动、z 轴排序,渲染引擎需要为特定的节点生成专用的涂层,生成一棵 LayerTree 并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,就从属于父节点的图层
拥有层叠上下文属性的元素会被提升为单独的一层,裁剪的元素也会成为单独一层
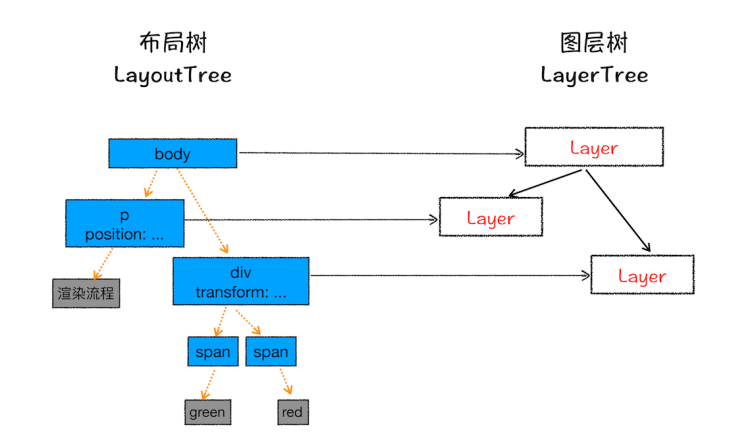
图层绘制
渲染引擎将一个图层的绘制拆分成很多小的绘制指令,按顺序组成一个待绘制列表,在这个阶段我们获得一个待绘制列表 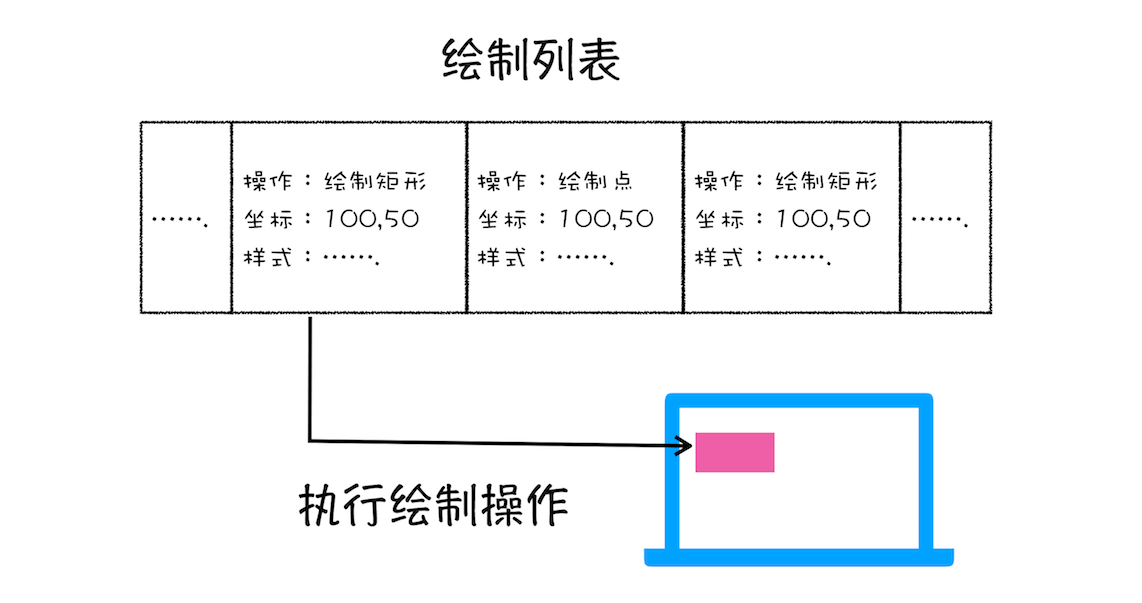
合成线程
栅格化操作
一个页面可能会很大,但是用户只能基于视口看到一部分,因此没有必要用巨大的开销去渲染整个页面。 于是乎,当绘制列表产出后,主线程把绘制列表提交给合成线程,合成线程会将图层划分为 图块(tile) ,通常是 256x256 或者 512x512,合成线程会按照视口附近的图块优先生成位图, 实际生成位图的操作是由栅格化执行,将图块转换为位图 。 渲染进程维护一个栅格化的线程池,图块的栅格化都在线程池里执行 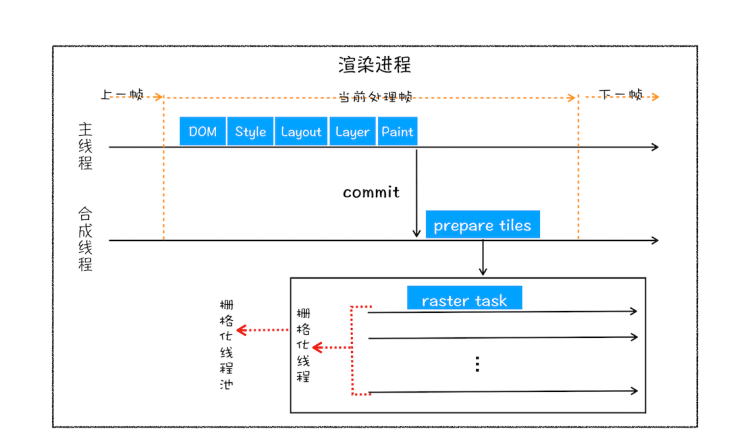 栅格化会使用 gpu 来加速,称为快速栅格化,或 gpu 栅格化,生成的位图被保存在 gpu 内存中
栅格化会使用 gpu 来加速,称为快速栅格化,或 gpu 栅格化,生成的位图被保存在 gpu 内存中 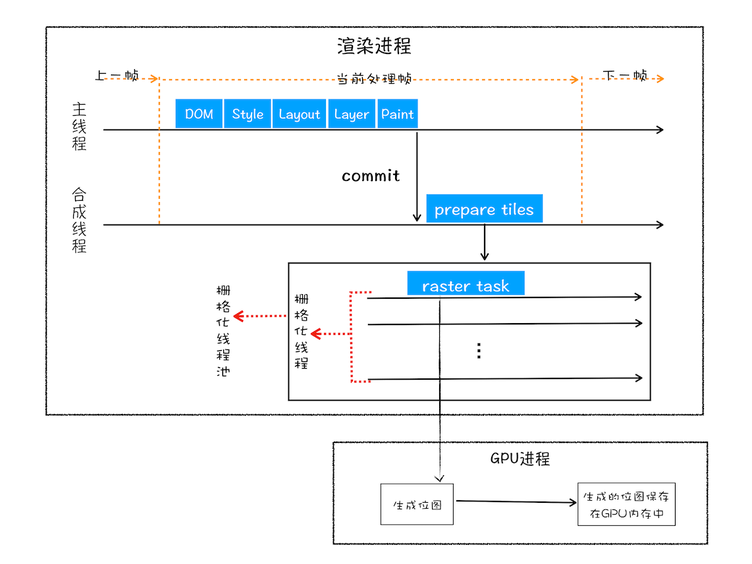
合成 compositing
合成线程收集图块信息(也叫绘制四边形 DrawQuad),然后进行合成帧操作,并将合成帧递交给主进程,最后浏览器主进程将合成帧发送给 GPU 进程,将页面内容绘制到内存中,最后将内存中的内容显示在屏幕上,变成肉眼可见的图像 浏览器有一个叫 viz 的组件,用来接收合成线程发来的 DrawQuad 命令,根据 DrawQuad 命令,将页面内容绘制到内存中,最后将内存显示在屏幕上,变成肉眼可见的图像
绘制的抽象理解
把每一个元素对应的盒变成位图,在内存中。把模型变为位图 可分为两类:图形和文字
- 图形:背景、边框、SVG 元素、阴影,需要底层库支持,Android 有 Skia,Windows 有 GDI
- 文字:分像素字形和矢量字形两种,小尺寸如 6px、8px 提供像素字形,大尺寸提供矢量字形。需要字体库支持,比如 C++编写的 Freetype,提供读取字体文件的基本能力,能够根据字符的码点抽取出字形
渲染时,最普遍的情况是生成的位图尺寸跟它在上一步排版时占据的尺寸相同。 但是很多属性会影响位图的大小,比如阴影,因此阴影会作为一个独立的盒来处理
渲染过程中,子元素是不会被绘制到渲染的位图上的,这样能够在父子元素的相对位置发生变化时,保证渲染的结果能够最大程度被缓存,减少重新渲染。 绘制过程,不会把子元素渲染到位图,合成正是为了创建合成的位图,把部分子元素渲染到合成的位图上
合成策略
<div id="a">
<div id="b">...</div>
<div id="c" style="transform:translate(0,0)"></div>
</div>猜测可能变化的元素,排除到合成之外,从而提高性能 假设以上代码要对 c 元素进行改变,此时如果合成 a 和 b,不合成 c,就能减少绘制次数,产生极大的性能收益 目前,合成策略根据 position、transform 等属性来决定,但是新的 css 标准给出了 will-change 属性,可以结合业务代码提示浏览器的合成策略。 will-change mdn
显示
浏览器会把最终要显示的位图交给操作系统处理 借助脏矩形算法,当鼠标移、元素移动或者其他需要导致重绘的场景发生时,只重新绘制它所影响到的几个矩形区域,重绘脏矩形区域时,把所有与矩形区域有交集的合成层(位图)的交集部分绘制即可。
参考:
- 输入一个 url 后会发生什么
- 渲染页面-mdn
- 浏览器渲染
- 重学前端-模块三:浏览器实现原理与 API
- 浏览器工作原理与实践-李兵
关于浏览器工作流程的思维导图、ppt
浏览器 window 对象
所谓的 BOM(Browser Object Model)浏览器对象模型 ,是为了控制浏览器的行为而出现的接口。 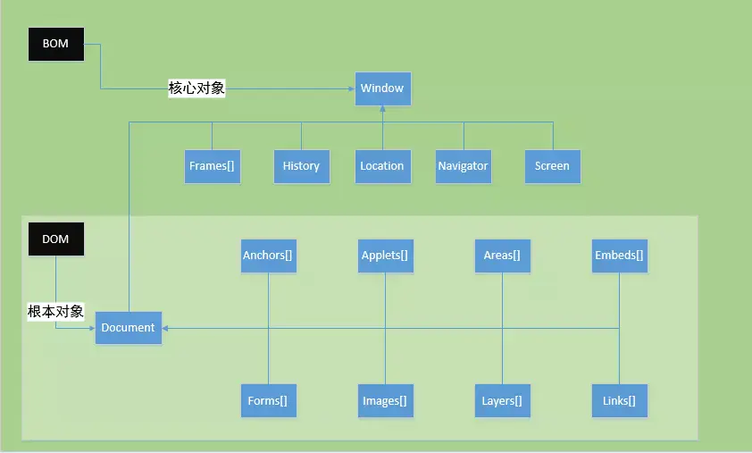 属于 BOM 区域的有浏览器标签页、地址栏、滚动条、右键菜单等等 BOM 的 核心对象 是 Window ,包含了 DOM 的核心对象 document window 不仅是全局作用域,还表示浏览器窗口 常用的 BOM API:
属于 BOM 区域的有浏览器标签页、地址栏、滚动条、右键菜单等等 BOM 的 核心对象 是 Window ,包含了 DOM 的核心对象 document window 不仅是全局作用域,还表示浏览器窗口 常用的 BOM API:
innerWidthinnerHeight可以获取浏览器窗口内部去除掉菜单栏、工具栏、边框等后的宽高,outerWidthouterHeight获取浏览器窗口的整个宽高navigator表示浏览器的信息
navigator.appName:浏览器名称; navigator.appVersion:浏览器版本; navigator.language:浏览器设置的语言; navigator.platform:操作系统类型; navigator.userAgent:浏览器设定的User-Agent字符串。 但是 navigator 的信息很容易可以修改,所以不一定是正确的,不要用这个去判断浏览器版本 正确做法是直接用||短路运算符
screen表示屏幕信息,常用属性有
screen.width:屏幕宽度,以像素为单位; screen.height:屏幕高度,以像素为单位; screen.colorDepth:返回颜色位数,如 8、16、24。
location对象表示当前页面的 url 信息
http://www.example.com:8080/path/index.html?a=1&b=2#TOP可以用location.href获取完整的 url。要获得 URL 各个部分的值,可以这么写:
location.protocol; // 'http'
location.host; // 'www.example.com'
location.port; // '8080'
location.Javapathname; // '/path/index.html'
location.search; // '?a=1&b=2'
location.hash; // 'TOP'location.assign()加载一个新页面,location.reload()重新加载当前页面 参考
document 文档对象
表示当前页面,document对象是整个 dom 树的根节点 常用方法: document.title获取 title 标签属性 getElementById()getElementsByTagName()document.querySelector()document.addEventListener()document.cookie获取当前页面的 Cookie,cookie 由服务器发送的 key-value 标识符,可用于区分不同用户的请求,服务器发送一个 cookie 给浏览器,浏览器访问该网站就会在请求头上附上这个 cookie。但是有安全隐患,因为 html 可以直接引用第三方的 js 代码,解决这个问题需要服务器设置 cookie 时使用 httponly
DOM 事件和事件委托
DOM 事件模型
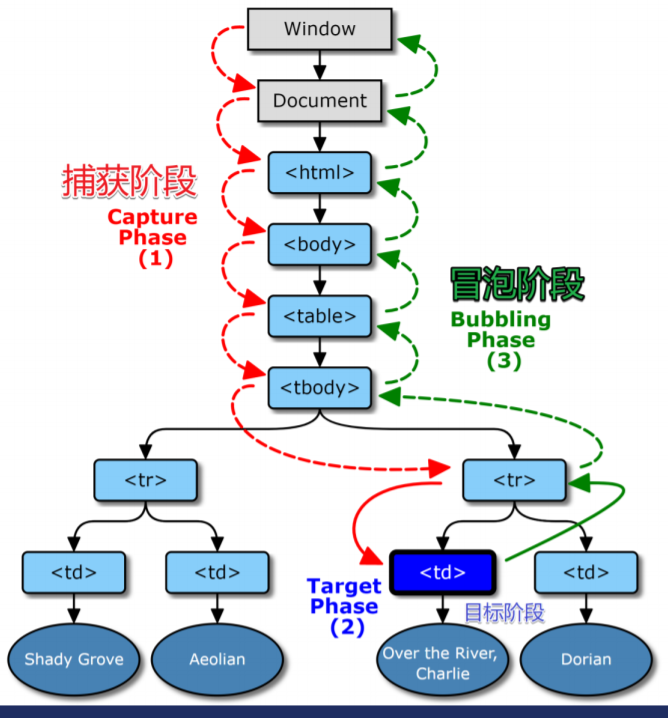 DOM 模型用一个逻辑树来表示一个文档,树的每个分支的终点都是一个节点(node),每个节点都包含着对象(objects)。DOM 的方法(methods)让你可以用特定方式操作这个树,用这些方法你可以改变文档的结构、样式或者内容。节点可以关联上事件处理器,一旦某一事件被触发了,那些事件处理器就会被执行。
DOM 模型用一个逻辑树来表示一个文档,树的每个分支的终点都是一个节点(node),每个节点都包含着对象(objects)。DOM 的方法(methods)让你可以用特定方式操作这个树,用这些方法你可以改变文档的结构、样式或者内容。节点可以关联上事件处理器,一旦某一事件被触发了,那些事件处理器就会被执行。
捕获和冒泡:
Netscape 认为 outer 上的处理函数应该先被执行. 这被称作 event capturing,即从外到内
IE 则认为 inner 上的处理函数具有执行优先权. 这被叫做 event bubbling,即从内到外
于是 W3C 标准则取其折中方案. W3C 事件模型中发生的任何事件, 先(从其祖先元素 document)开始一路向下捕获, 直到达到目标元素, 其后再次从目标元素开始冒泡.(先捕获再冒泡,搞清楚这一点很重要)
开发者可以决定事件处理器是注册在捕获或者是冒泡阶段. 如果 addEventListener 的最后一个参数是 true, 那么处理函数将在捕获阶段被触发; 否则(false), 会在冒泡阶段被触发.
也就是每点击一个元素,以点击的元素为中心,先捕获,再冒泡,false 或者不加参数表示注册在冒泡阶段执行,true 表示注册在捕获阶段执行
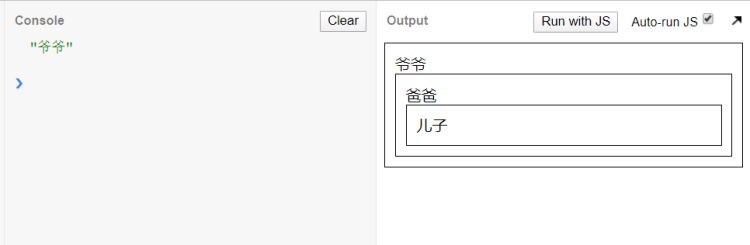
示例:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>JS Bin</title>
</head>
<body>
<div id="grand1">
爷爷
<div id="parent1">
爸爸
<div id="child1">儿子</div>
</div>
</div>
</body>
</html>grand1.addEventListener(
'click',
function f1() {
console.log('爷爷');
},
false
); //冒泡
parent1.addEventListener(
'click',
function f1() {
console.log('爸爸');
},
true
); //捕获
child1.addEventListener(
'click',
function f3() {
console.log('儿子冒泡');
},
false
); //冒泡
child1.addEventListener(
'click',
function f3() {
console.log('儿子捕获');
},
true
); //捕获结果依次为:
- 点击儿子
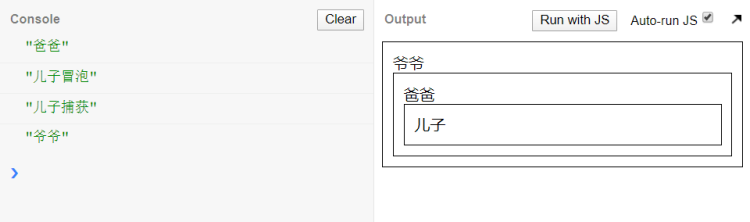
- 点击爸爸
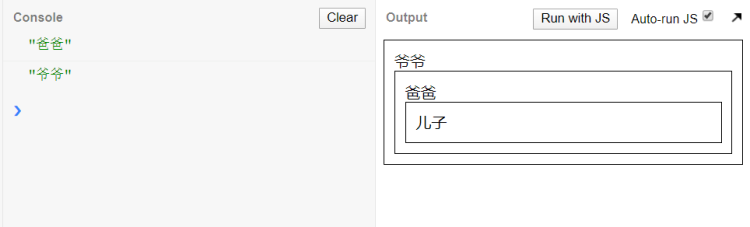
- 点击爷爷
事件委托
事件委托,通俗地来讲,就是把一个元素响应事件(click、keydown......)的函数委托到另一个元素,好处是节省了内存还能够动态监听元素
一般来讲,会把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,当事件响应到需要绑定的元素上时,会通过事件冒泡机制从而触发它的外层元素的绑定事件上,然后在外层元素上去执行函数。
示例:
<div id="test">
<div class="red">hi</div>
<div class="red">hi</div>
<div class="red">hi</div>
<div class="red">hi</div>
<div class="red">hi</div>
</div>
delegateEvent(parentSelector, targetSelector, events, fn) {
// 事件处理逻辑,
parentSelector.addEventListener(parentSelector, events, function (e) {
let targetEl = e.target
const currentTarget = e.currentTarget;
// 遍历并判断是否为目标元素,如果不是,则往元素的 parentNode 继续查找
while (!targetEl.matches(targetSelector)) {
// 如果是目标元素则跳出循环
if (targetEl === currentTarget) {
targetEl = null;
break;
}
targetEl = targetEl.parentNode;
}
if (targetEl) {
// 将回调函数的 this 指向目标元素
fn.call(targetEl, Array.prototype.slice.call(arguments));
}
});
}const test = document.querySelector('#test');
dom.delegateEvent(test, '#test .red', 'click', () => {
console.log('我被点击了');
});history 对象
window.history ,保存了浏览器的历史记录,js 可以调用 history 对象的 back() or forward(),相当于点击浏览器的后退和前进,这个在现代 web 复杂的页面交互中是不适用的
浏览器兼容性问题
样式兼容性

使用 Normalize.css 或是自己撰写 reset 重置样式
不同浏览器厂商对于 css3 的样式提供了针对浏览器的前缀
内核 浏览器代表 前缀 Trident IE -ms Gecko Firefox -moz Presto 已废弃 Opera 前内核 -o Webkit Chrome、Safari -webkit opacity
opacity: 0.5;
filter: alpha((opacity = 50)); //IE6-IE8我们习惯使用filter滤镜属性来进行实现
filter: progid: DXImageTransform.Microsoft.Alpha((style = 0), (opacity = 50)); //IE4-IE9都支持滤镜写法progid:DXImageTransform.Microsoft.Alpha(Opacity=xx)交互兼容性
 事件兼容: 适配器写法
事件兼容: 适配器写法
var helper = {};
//绑定事件
helper.on = function (target, type, handler) {
if (target.addEventListener) {
target.addEventListener(type, handler, false);
} else {
target.attachEvent(
'on' + type,
function (event) {
return handler.call(target, event);
},
false
);
}
};
//取消事件监听
helper.remove = function (target, type, handler) {
if (target.removeEventListener) {
target.removeEventListener(type, handler);
} else {
target.detachEvent(
'on' + type,
function (event) {
return handler.call(target, event);
},
true
);
}
};浏览器 hack
 不同厂商的浏览器或者同一浏览器的不同版本都可能存在对 css、js 的支持、解析不一样,为了获得统一的效果,就要针对不同的浏览器或不同版本写特定的 css 或 js 有 css hack 和 js hack 发现一个便于查询的网站https://www.html.cn/tool/hack/ 但是需要注意 hack 并不总是完美的解决方案,大多数情况下应该修复 css/js 可以使用modernizr库进行功能检测,还有中文网modernizr
不同厂商的浏览器或者同一浏览器的不同版本都可能存在对 css、js 的支持、解析不一样,为了获得统一的效果,就要针对不同的浏览器或不同版本写特定的 css 或 js 有 css hack 和 js hack 发现一个便于查询的网站https://www.html.cn/tool/hack/ 但是需要注意 hack 并不总是完美的解决方案,大多数情况下应该修复 css/js 可以使用modernizr库进行功能检测,还有中文网modernizr